What Are Kubernetes Operators? (Operators 101: Part 1)
If you've used Kubernetes in just about any capacity over the past few years, you've almost certainly leaned on at least one operator to automate a piece of your infrastructure.
The operator model has been espoused by influencers like Viktor Farcic (aka @DevOps Toolkit on YouTube) and Kelsey Hightower for its advanced automation abilities. OperatorHub.io lists over 300 different operators for you to install in your clusters. Kubernetes operators seem to be everywhere!
But what exactly is an operator? The official documentation page about operators is actually fairly short and leaves a lot to the reader's imagination.
This is the start of a new series, Operators 101, where I will teach readers how to design, build, and deploy Kubernetes operators that can automate the management of your own unique applications.
For a real-world case study of the benefits that the operator pattern has over traditional k8s resource management techniques, check out this article that I wrote which discusses the benefits of moving my company's SaaS infrastructure to a Kubernetes operator.
The Operator Pattern
What makes Kubernetes operators so difficult to describe is that they are not just one discrete unit. Instead, an operator is actually comprised of several distinct components!
When trying to explain what operators are to people who haven't dealt with them before, I like to describe them as new native Kubernetes resources that enable you to automate system components based on the resources' state and your own custom logic.
At a minimum, an operator consists of a Custom Resource Definition (which defines your custom object's schema) and a Controller that performs actions based on the state of Custom Resources created from your definition. I like to think of a Custom Resource Definition (or abbreviated CRD) as analogous to a class definition in Java, and a Custom Resource can be thought of as an instance of that class.
To provide a more concrete example of how these components work together, let's investigate how a commonly-used Kubernetes resource works under the hood and then relate this back to the operator pattern.
Analogy: How a Deployment Works
A Deployment's schema can be found in the Kubernetes API specification in the apps/v1 group. You can check out the full spec in the Kubernetes reference documentation, here. This spec contains the definition of a Deployment kind, or schema, which includes all of its fields, their descriptions, and types. I like to think of this schema as a Go struct; a container that can hold structured data of a particular shape. This API spec, or schema, is equivalent to a Custom Resource Definition in an operator, which defines the fields of your new Custom Resource and its metadata.
Continuing the analogy, when you want to create a Deployment, one could write a yaml (or json) file that uses the Deployment API schema. Here's a simple example:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
containers:
- name: nginx
image: nginx:1.23.3This yaml file represents a Custom Resource, or an instance of your Custom Resource Definition.
When you kubectl create -f the file, the kubectl client sends a POST request to the Kubernetes API server with these file contents in the request body. Once the request has been validated, the server adds the new Deployment object to the Kubernetes control plane's key-value database, etcd.
Elsewhere in the control plane, there is a Deployment Controller that has registered itself with the Kubernetes API server to listen for adds, modifications, or deletes for any Deployment in the cluster. Once it has been notified, the controller will then run a reconciliation loop to migrate the current cluster state to its desired state, as specified by the mutated object. This is similar to how declarative programming languages, like Terraform, work.
Getting back to our example, once the API server has stored the new Deployment spec in etcd, the Deployment Controller will be notified about the newly created resource. This will trigger a reconciliation between the current state of the cluster (where the Deployment and its underlying ReplicaSet do not exist) and the desired state of Deployment, as defined by the spec stored in etcd.
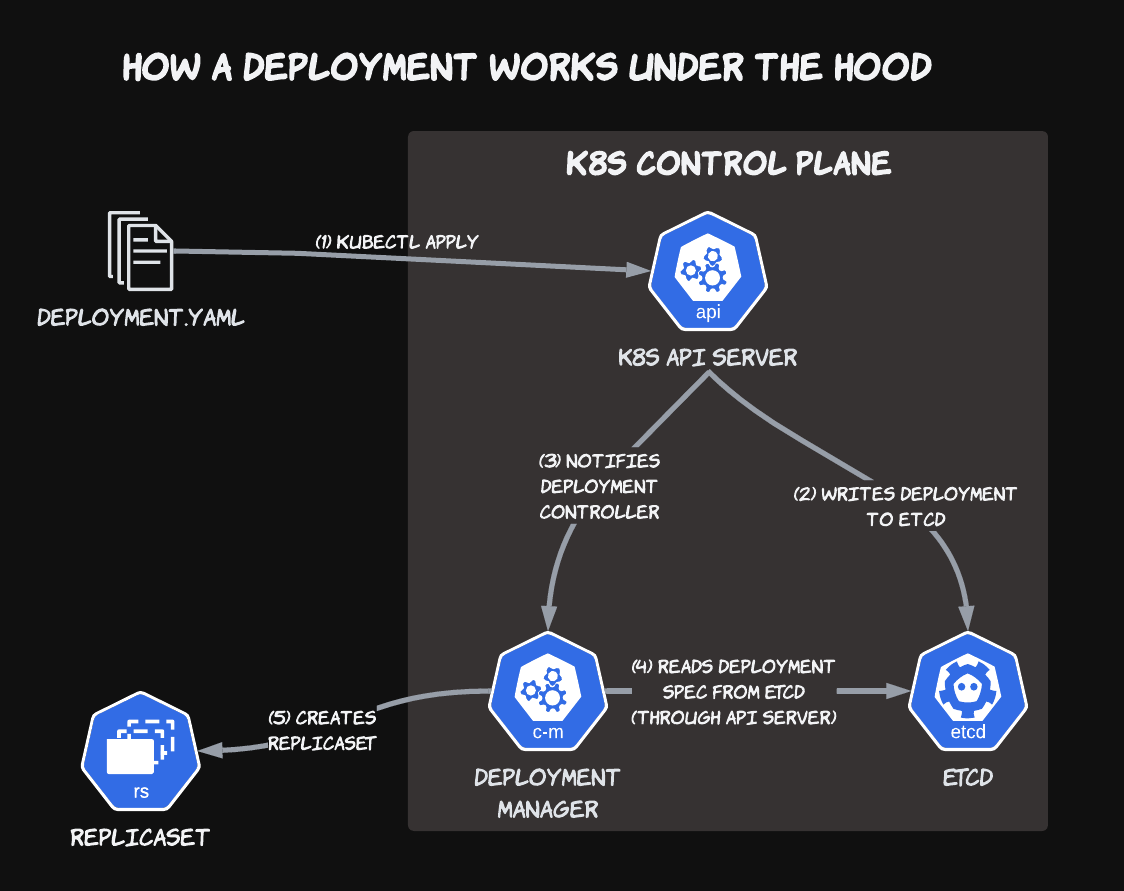
It's important to note that the Deployment Manager does not directly talk to etcd. All communication with the cluster data store happens through the API server. I just added the step (4) line for clarity in this initial example. All future diagrams will display the correct data flow.
Since the Deployment did not previously exist, the ReplicaSet that it is supposed to control also does not exist. So in its reconciliation loop, the Deployment Controller will create a new ReplicaSet based on the Pod template portion and the number of replicas in the Deployment spec. Once the ReplicaSet has been created, the controller's job now is to reconcile this ReplicaSet with the Deployment's spec whenever a change to the Deployment spec occurs.
For example, lets say that you want increase the desired number of replicas to 2 by changing the yaml to:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 2 ## changed from 1
containers:
- name: nginx
image: nginx:1.23.3Once you kubectl apply this yaml, sending a POST request to the API server, the Deployment Controller will be notified about this new change. It will perform another reconciliation of the underlying ReplicaSet, see that there is only 1 replica compared to the desired number of replicas (2) as per the Deployment spec, and modify the underlying ReplicaSet to increase the number of replicas to 2.
Composability
What makes this model so powerful is the inherent composability of Kubernetes primitives. In the above example, the Deployment Controller has one very specific job: to manage ReplicaSets. But as users, we don't typically directly interact with ReplicaSets. Instead, we're much more concerned with the state of Pods managed by a ReplicaSet, the runtimes where our applications live and breathe.
The work of actually managing Pods by scaling them up-and-down is the responsibility of the ReplicaSet controller. So the Deployment Controller delegates that work to the ReplicaSet controller, and trusts that it will do the right thing when a Deployment's desired number of replicas changes.
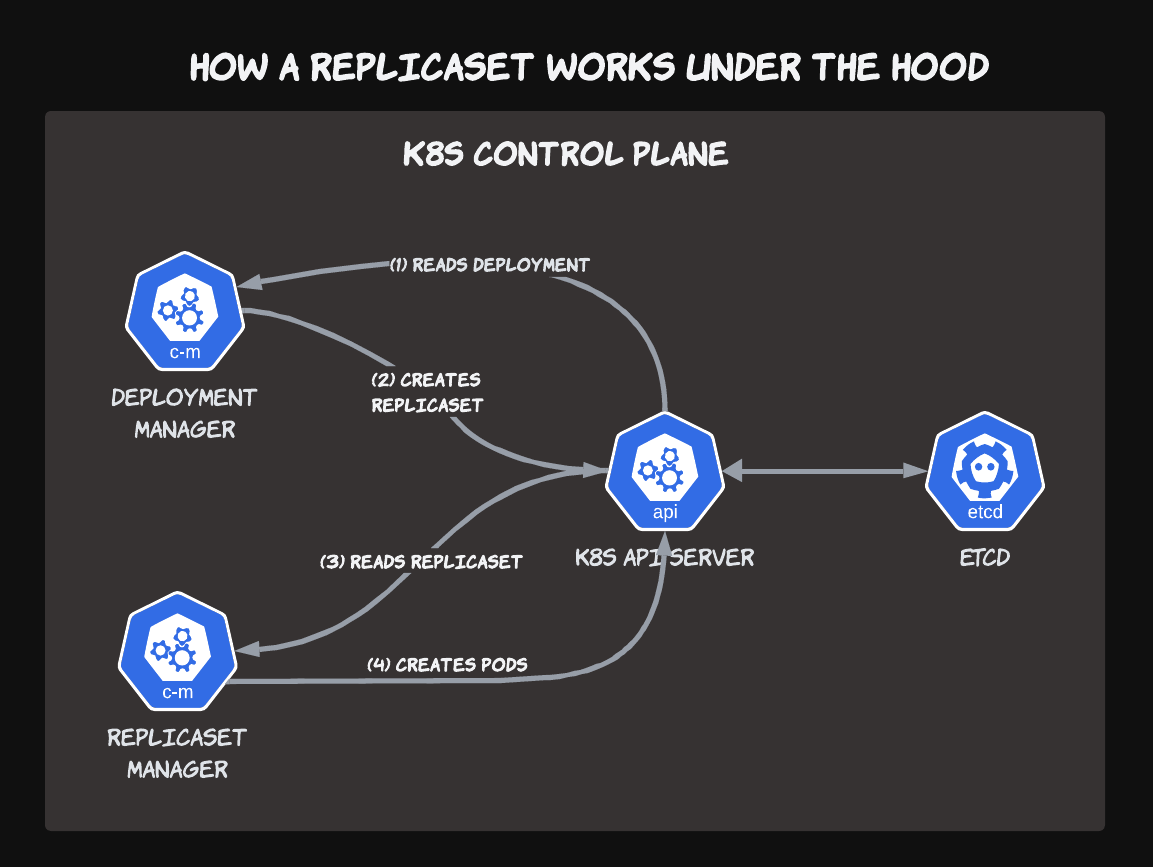
As operator writers, we can use this property to rely on existing Kubernetes primitives to handle single tasks and combine various components to perform more complex automation to solve our own unique problems. Which specific components we use and how we link them together is determined by you, the writer of the operator.
So What Is An Operator?
Now that we're familiar with how Deployments, and other Kubernetes resources, work under the hood, we can finally get to a clearer definition of a Kubernetes operator.
To work with any Kubernetes resource, we know that we need three components:
- An API Schema (like the Deployments API spec in the apps/v1 group)
- A concrete instance of that schema (a Deployment resource stored in etcd)
- A controller that performs reconciliation actions based on a resource's state
An operator is a combination of these three components, designed to orchestrate a custom schema that you create in a way that you write. So in operator terms, these components are:
- A Custom Resource Definition that defines your new resource's schema
- Custom Resources which are instances of your new resource type
- A Controller that performs automation actions based on the state of Custom Resources
Now you see how an operator is not just a single thing, but actually a combination of several pieces that work together. The idea of multiple smaller components working together to accomplish larger tasks is fundamental to not just how operators work, but also to how the entire Kubernetes ecosystem operates. By writing an operator of your own, you will not just gain additional automation benefits, but you will also grasp a deeper understanding of how Kubernetes works under the hood.
Stay Tuned!
I hope that this article has provided some clarity into what operators are and why they can be a powerful tool in your automation toolbox. The next article in this series will present a sample Custom Resource Definition and discuss how this new spec can drive your own custom automation.
If you like this content and want to follow along with the series, I'll be writing more articles under the Operators 101 tag on this blog.