An Introduction to Custom Resource Definitions and Custom Resources (Operators 101: Part 2)
Check out Part 1 of this series for an introduction to Kubernetes operators.
Now that we've covered the basics of what a Kubernetes operator is, we can start to dig into the details of each operator component. Remember that a Kubernetes operator consists of 3 parts: a Custom Resource Definition, a Custom Resource, and a Controller. Before we can focus on the Controller, which is where an operator's automation takes place, we first need to define our Custom Resource Definition and use that to create a Custom Resource.
Example: RSS Feed Reader Application
Throughout this series, I will be using a distributed RSS feed reader application (henceforth known as "FeedReader") to demonstrate basic Kubernetes operator concepts. Let's start with a quick overview of the FeedReader design.
FeedReader Architecture
The architecture for our FeedReader application is split into 3 main components:
- A StatefulSet running our feed database. This holds both the URLs of feeds that we wish to scrape, as well as their scraped contents
- A CronJob to perform the feed scraping job at a regular interval
- A Deployment that provides a frontend to query the feed database and display RSS feed contents to the end user
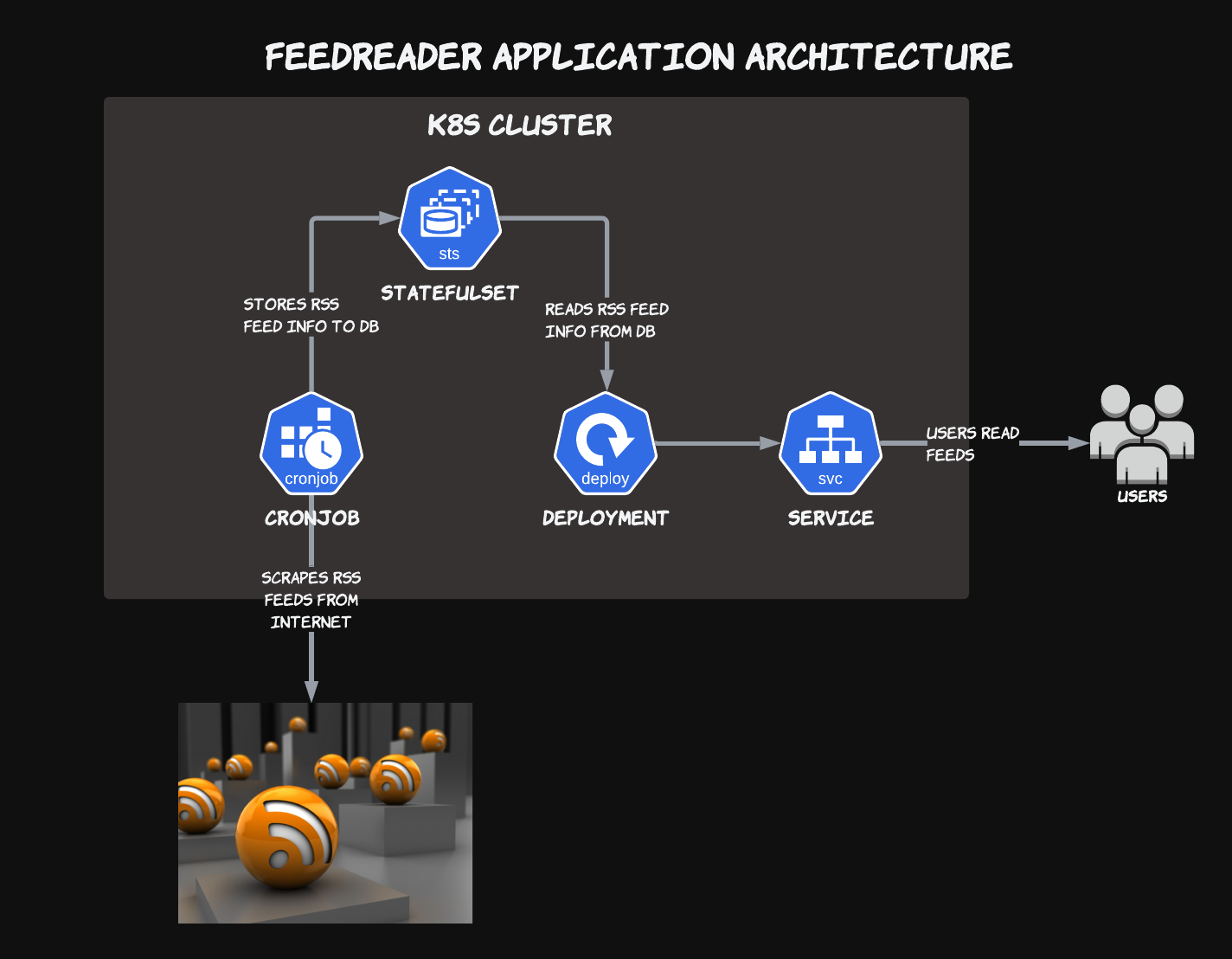
The FeedReader application runs as a single golang binary that has 3 modes: web server, feed scraper, and embedded feed database. Each of these modes is designed to run in a Deployment, CronJob, and StatefulSet respectively.
Back to CRDs: Starting At the End
Just to recap, a Custom Resource Definition is the schema of a new Kubernetes resource type that you define. But instead of thinking in terms of an abstract schema, I believe that it's easier to start from your desired result (a concrete Custom Resource) and work backwards from there.
My very basic rule of thumb is that whenever you need a variable to describe an option in your application, you should consider defining a new field and setting sample value in a Custom Resource to represent it. Once you have a Custom Resource with fields and values that clearly explain your application's desired behavior, you can then start to generalize these fields into an abstract schema, or CRD.
Let's perform this exercise with the FeedReader.
FeedReader CRD
To keep the article at a readable length, I'm just going focus on the most critical aspects of the FeedReader. I've extracted two key variables that are required for the application to function at its most basic level:
- A list of RSS feed urls to scrape
- A time interval that defines how often to scrape the urls in the above list
Thus, I'll add 2 fields to my FeedReader CR:
- A list of strings that hold my feed urls
- A Golang duration string that specifies the scrape interval
Based on these two requirements, here's an example of a FeedReader Custom Resource that I would like to define:
---
apiVersion: crd.sklar.rocks/v1alpha1
kind: FeedReader
metadata:
name: feed-reader-app
spec:
feeds:
- https://sklar.rocks/atom.xml
scrapeInterval: 60mOnce created, the above resource should deploy a new instance of the FeedReader app, add one feed (https://sklar.rocks/atom.xml) to the database, and scrape that url every 60 minutes for new posts that are not currently in the feed database.
Note that I could use something like crontab syntax to define the scrape interval, but I find the golang human-readable intervals easier to work with, since I don't always have to cross-check with crontab.guru to make sure that I've defined the correct schedule.
Exercise
Can you think of any more options that the FeedReader would need? Personally, I would start with things like feed retention, logging, and scraping retry behavior, but the possibilities are endless!
From Instance to Schema
But before we can kubectl apply on the above CR yaml, we first need to define and apply a schema in the form of a Custom Resource Definition (CRD) for us to create an object of this type in our Kubernetes cluster. Once the CRD is known to our cluster, we can then create and modify new instances of that CRD.
If you've ever worked with OpenAPI, Swagger, XML Schema or any other schema definition, you probably know that in many cases, the schema of an object can be incredibly more verbose than an instance of the object itself. In Kubernetes, to define a simple Custom Resource Definition with the two fields that I outlined above, the yaml would look something like this:
---
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: feedreaders.crd.sklar.rocks
spec:
group: crd.sklar.rocks
names:
kind: FeedReader
listKind: FeedReaderList
plural: feedreaders
singular: feedreader
scope: Namespaced
versions:
name: v1alpha1
schema:
openAPIV3Schema:
properties:
apiVersion:
description: 'APIVersion defines the versioned schema of this representation
of an object. Servers should convert recognized schemas to the latest
internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources'
type: string
kind:
description: 'Kind is a string value representing the REST resource this
object represents. Servers may infer this from the endpoint the client
submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds'
type: string
metadata:
type: object
spec:
properties:
feeds:
description: List of feed urls to scrape at a regular interval
items:
type: string
type: array
scrapeInterval:
description: 'Interval at which to scrape feeds, in the form of a
golang duration string (see https://pkg.go.dev/time#ParseDuration for valid formats)'
type: string
type: object
status:
properties:
lastScrape:
description: Time of the last scrape
format: date-time
type: string
type: object
type: object
served: true
storage: true
subresources:
status: {}Now that's a lot of yaml! This schema includes metadata like the resource's name, API group, and version, as well as the formal definitions of our custom fields and standard Kubernetes fields like "apiVersion" and "kind".
If you're thinking "do I actually have to write something like this for all of my CRDs?", the answer is no! This is where we can leverage the Kubernetes standard library and golang tooling when defining CRDs. For example, I didn't have to write a single line of the yaml in the example above! Here's how I did it.
Controller-gen to the Rescue
The Kubernetes community has developed a tool to generate CRD yaml files directly from Go structs, called controller-gen. This tool parses Go source code for structs and special comments known as "markers" that begin with //+kubebuilder. It then uses this parsed data to generate a variety of operator-related code and yaml manifests. One such manifest that it can create is a CRD.
Using controller-gen, here's the code that I used to generate the above schema. It's certainly much less verbose than the resulting yaml file!
package v1alpha1
import metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
type FeedReaderSpec struct {
// List of feed urls to scrape at a regular interval
Feeds []string `json:"feeds,omitempty"`
// Interval at which to scrape feeds, in the form of a golang duration string
// (see https://pkg.go.dev/time#ParseDuration for valid formats)
ScrapeInterval string `json:"scrapeInterval,omitempty"`
}
type FeedReaderStatus struct {
// Time of the last scrape
LastScrape metav1.Time `json:"lastScrape,omitempty"`
}
//+kubebuilder:object:root=true
//+kubebuilder:subresource:status
type FeedReader struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec FeedReaderSpec `json:"spec,omitempty"`
Status FeedReaderStatus `json:"status,omitempty"`
}
//+kubebuilder:object:root=true
type FeedReaderList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []FeedReaderList `json:"items"`
}
Here, we've defined a FeedReader struct that has a Spec and a Status field. Seem familiar? Almost every Kubernetes resource that we deal with has a .spec and .status field in its definition. But the types of our FeedReader's Spec and Status are actually custom types that we defined directly in our Go code. This gives us the ability to craft our CRD schema in a compiled language with static type-checking while letting the tooling emit the equivalent yaml CRD spec to use in our Kubernetes clusters.
If you compare the CRD yaml with the FeedReaderSpec struct, you can see that controller-gen extracted the struct fields, types, and docstrings into the emitted yaml. Also, since our FeedReader inherits from metav1.TypeMeta and metav1.ObjectMeta and is annotated with the //+kubebuilder:object:root=true comment, the fields from those interfaces (like apiVersion and kind) are included in the yaml as well.
But what about things like the API group, crd.sklar.rocks, and version v1alpha1? These are handled in a separate Go file in the same package:
// +kubebuilder:object:generate=true
// +groupName=crd.sklar.rocks
package v1alpha1
import (
"k8s.io/apimachinery/pkg/runtime/schema"
"sigs.k8s.io/controller-runtime/pkg/scheme"
)
var (
// GroupVersion is group version used to register these objects
GroupVersion = schema.GroupVersion{Group: "crd.sklar.rocks", Version: "v1alpha1"}
// SchemeBuilder is used to add go types to the GroupVersionKind scheme
SchemeBuilder = &scheme.Builder{GroupVersion: GroupVersion}
)
func init() {
SchemeBuilder.Register(&FeedReader{}, &FeedReaderList{})
}Here, we initialize a GroupVersion instance that defines our API group (crd.sklar.rocks) and version (v1alpha1). We then use it to instantiate the SchemeBuilder, which is used to register the FeedReader and FeedReaderList structs from above. When controller-gen is run, it will load this Go package, check for any registered structs, parse them (and any related comment markers), and emit the CRD yaml that we can use to install the CRD in our cluster.
Assuming that our api definitions are in the ./api directory and we want the output in ./deploy/crd, all we need to do is run the following command to generate our FeedReader CRD's yaml definition:
$ controller-gen crd paths="./api/..." output:dir=deploy/crdInstalling our Custom Resource Definition
Now that we've generated our Custom Resource Definition, how do we install it in the cluster? It's actually very simple! A CustomResourceDefinition is its own Kubernetes resource type, just like a Deployment, Pod, StatefulSet, or any of the other Kubernetes resources that you're used to working with. All you need to do is kubectl create your CRD yaml, and the new CRD will be validated and registered with the API server.
You can check this by typing kubectl get crd, which will list all of the Custom Resource Definitions installed in your cluster. If you've copy-pasted the CRD yaml and installed the FeedReader CRD in your cluster, you should see the feedreader.crd.sklar.rocks in the list, under the v1alpha1 API version.
With our FeedReader CRD installed, you are free to create as many resources of kind: FeedReader as you wish. Each one of these represents a unique instance of the FeedReader application in your cluster, with each instance managing its own Deployment, StatefulSet and CronJob. This way, you can easily deploy and manage multiple instances of your application in your cluster, all by creating and modifying Kubernetes objects in the same way that you would for any other resource type.
What's Next?
Now that we have a Custom Resource Definition and a Custom Resource that defines our FeedReader application, we need to actually perform the orchestration that will manage the application in our cluster. Stay tuned for the next article in this series, which will discuss how to do that in a custom controller.
If you like this content and want to follow along with the series, I'll be writing more articles under the Operators 101 tag on this blog.